내 채팅 시스템에 Kafka를 먼저 도입하기 전에 kafka가 어떤 건지 부터 알아가는 시간을 가져보자!!
Apache Kafka
- 실시간으로 스트림 데이터를 수집하고 처리하는 데 최적화된 ‘분산 이벤트 스트리밍 플랫폼(Distributed Data Streaming Platform)'
- 이는 실시간으로 발생하는 대량의 데이터를 중앙 허브를 통해 흐르도록 설계되어 있다.
- 데이터의 일관성을 유지하고 시스템 전반의 복잡성을 줄일 수 있음.
- 이러한 다량의 데이터는 A 지점에서 B 지점까지만의 데이터가 이동되는 것뿐만 아니라, A 지점에서 Z지점까지의 필요한 모든 곳에 대규모 데이터를 동시에 전달할 수 있어서
- 현대적인 데이터 파이프라인 구축에 필수적인 도구로 자리잡았으며, Netflix, LinkedIn, Uber 등 많은 기업들이 핵심 인프라로 사용하고 있다고 한다.
https://aws.amazon.com/ko/what-is/apache-kafka/
Kafka란? - Apache Kafka 설명 - AWS
Apache Kafka는 실시간으로 스트리밍 데이터를 수집하고 처리하는 데 최적화된 분산 데이터 스토어입니다. 스트리밍 데이터는 수천 개의 데이터 원본에서 연속적으로 생성되는 데이터로, 보통 데
aws.amazon.com
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
[ 더 알아보기 ]
💡 Kafka에 의해 처리되는 스트림(Stream)과 스트리밍(Streaming)은 무엇일까?
- 스트림(Stream)이란 시간에 따라 연속적으로 발생하는 데이터의 흐름을 의미합니다.
- 예시) 실시간 주식 거래 데이터, SNS 피드, IoT 센서 데이터 등
- 스트리밍(Streaming)은 이러한 데이터 스트림을 실시간으로 처리하는 과정!!
💡 분산 이벤트 스트리밍 플랫폼(Distributed Event Streaming Platform)이란?
- 여러 서버에 걸쳐 이벤트 데이터를 실시간으로 처리하고 저장하는 시스템을 의미합니다.
- 주요한 특징은 분산 처리를 실시간으로 처리하며, 데이터 복제를 통해 장애 상황에서도 데이터 손실을 방지하며, 이벤트 발생 순서대로 처리하여 데이터의 일관성을 보장한다.
등장 배경
- 2011년 LinkedIn에서 처음 개발되었습니다. LinkedIn은 실시간으로 발생하는 대량의 사용자 활동 데이터(예: 프로필 조회, 메시지, 연결 요청 등)를 효율적으로 처리하고 분석해야 하는 과제에 직면했습니다.
Apache Kafka를 적용하기 전
Apache Kafka를 적용한 아키텍처
- 스트림 중심의 아키텍처로 구성이 되었고 이 설정에서 Kafka는 일종의 범용 데이터 파이프라인 역할을 한다.
- 각 시스템은 이 중앙 파이프라인에 공급하거나 공급받을 수 있다.
- 애플리케이션이나 스트림 프로세서는 이를 탭하여 새로운 파생 스트림을 생성할 수 있으며, 이는 다시 다양한 시스템에 공급되어 제공된다.
주요 특징
- 가장 주요한 특징은 '실시간 처리', '고가용성'
- 데이터를 실시간으로 처리하면서, 시스템이 장시간 동안 중단 없이 지속적으로 운영될 수 있는 능력을 의미
높은 처리량
- 대용량 실시간 로그 데이터를 처리하는데 적합하며, 초당 수백만 건의 메시지를 처리할 수 있다.
확장 가능
- 최대 1,000개의 브로커, 하루 수조 개의 메시지, 페티바이트 규모의 데이터, 수십만 개의 파티션까지 프로덕션 클러스터를 확장할 수 있으며, 저장소와 처리를 탄력젹으로 확장하고 축소할 수 있다.
낮은 지연 시간
- 실시간 데이터 파이프라인을 구성하는데 적합한 밀리초 단위의 지연시간을 제공한다.
높은 가용성
- 가용성 영역에 걸쳐 클러스터를 호율적으로 확장하거나 여러 지리적 영역에 걸쳐 있는 개별 클러스터를 연결
영속성
- 디스크에 데이터를 저장하거나 데이터 영속성을 보장하며, 데이터 손실을 방지
🔍 주요 사용 사례
1. 실시간 스트리밍 애플리케이션
- 실시간으로 발생하는 데이터를 지속적으로 처리하고 분석하는 애플리케이션
- 예를 들어 실시간 로그 분석, 실시간 모니터링 시스템 등
2. 데이터 파이프 라인
- 데이터를 안정적으로 처리하고 한 시스템에서 다른 시스템으로 이동하며, 스트리밍 애플리케이션은 데이터 스트림을 소비하는 애플리케이션
- 예를 들어서, 사용자 활동 데이터를 받아 사람들이 웹사이트를 어떻게 사용하는지 실시간으로 추적하는 데이터 파이프라인을 만들려면 Kafka를 사용하여 스트리밍 데이터를 수집 및 저장하면서 데이터 파이프라인을 구동하는 애플리케이션에 읽기 서비스를 제공할 수 있다.
3. 메시징 시스템(브로커)
- 애플리케이션 간의 메시지 전달을 중개하는 미들웨어 시스템입니다. 발신자(Producer)와 수신자(Consumer) 사이에서 메시지를 전달하는 중간 역할을 수행합니다.
| 사용 사례 | 설명 |
| 스트리밍 애플리케이션 | 실시간 데이터 스트림을 처리하는 애플리케이션을 구축하여 즉각적인 분석과 대응이 가능합니다. |
| 메시징 시스템 | 애플리케이션 간의 비동기 통신을 위한 메시지 브로커 역할을 수행하며, 시스템 간 안정적인 데이터 전달과 통신을 중재합니다. |
| 데이터 파이프라인 | 실시간 데이터를 수집하고 저장하면서 다른 시스템으로 안정적으로 전달하는 파이프라인을 구축합니다. |
| 활동 추적 | 웹사이트나 애플리케이션의 사용자 행동 데이터를 실시간으로 수집하고 분석하여 사용 패턴을 파악합니다. |
| 로그/메트릭 수집 | 여러 서비스의 로그와 성능 지표를 중앙 집중화하여 모니터링하고 관리합니다. |
⚒️ Apache Kafka vs RabbitMQ
- 주요한 차이점은 Kafka는 '분산 스트리밍 플랫폼'이고 RabbitMQ는 '메시지 브로커'
- 즉, Kafka의 경우 메시지 브로커의 역할도 수행하며, 데이터 스트림의 저장, 처리, 실시간 분석 등 광범위한 데이터 처리 기능을 제공하며 이는 더 포괄적인 개념이라고 할 수 있다.
| 특성 | Apache Kafka | RabbitMQ |
| 아키텍처 | 분산 스트리밍 플랫폼 | 메시지 브로커 |
| 프로토콜 | TCP를 이용한 바이너리 프로토콜 | 메시징 큐 프로토콜(AMQL) : MQTT, STOMP |
| 메시징 모델 | 발행-구독(Pub/Sub) 기반 스트리밍, 대기열(Queue) 모델 | 메시지 큐잉과 라우팅 중심 |
| 성능 | 대용량 데이터 처리에 최적화 (높은 처리량) | 낮은 지연시간, 중소규모 메시징에 적합 |
| 데이터 보존 | 설정된 기간동안 데이터 보존 (영속성) | 메시지 전달 후 즉시 삭제 |
| 확장성 | 수평적 확장이 용이, 대규모 확장 가능 | 수직적 확장 중심, 중소규모에 적합 |
| 사용 사례 | 로그 수집, 스트림 처리, 이벤트 소싱 | 마이크로서비스 간 통신, 작업 큐 |
| 메시지 순서 | 파티션 내에서 순서 보장 | FIFO 큐에서 순서 보장 |
| 복잡성 | 설정과 운영이 상대적으로 복잡 | 설정과 운영이 비교적 간단 |
Apacke Kafka 모델
1. 대기열(Queue) 모델
- 생성자(Producer)가 생성한 데이터를 여러 소비자(Consumer)에게 분산하는 기능을 합니다. 해당 모델은 여러 소비자(Consumer)가 동시에 구독할 수 없다는 한계가 있습니다.
- 즉, 생성자는 데이터를 큐에 적재하고 큐에서는 순차적으로 데이터가 추출되기에 모든 소비자에게 동시에 전달이 아닌 순차적으로 전달이 됩니다.
- 이를 통해서 순서가 보장이 되며, 메시지 중복 처리를 방지하고 작업을 분산하는데 효과적인 방법입니다.
💡 대기열(Queue) 모델 처리 과정
1. 생성자(Producer) → 데이터(Data) → 대기열(Queue)
- 생성자는 애플리케이션이나 서비스를 의미하며, 대기열(Queue)로 스트림 데이터를 전송합니다.
- 전송된 데이터는 대기열(Queue)에 FIFO(First In First Out) 형태로 순차적으로 적재가 됩니다.
2. 대기열(Queue) → 소비자(Consumer)
- 대기열(Queue)에 있는 데이터는 소비자(Consumer)가 하나씩 가져가서 처리합니다.
- 데이터는 순차적으로 처리되며, 하나의 데이터는 하나의 소비자에 의해서만 처리됩니다.
- 소비자가 데이터를 성공적으로 처리하면 해당 데이터는 대기열에서 제거됩니다.
2. 게시-구독(Publish-Subscribe) 모델
- 게시자(Publisher)가 발행한 메시지를 여러 소비자(Consumer)가 동시에 구독하고 처리할 수 있다. 각 소비자는 독립적으로 메시지를 받아 처리할 수 있다.
- 작업 부하를 분산하기 위해서는 각 구독자가 서로 다른 메시지를 처리해야 하는데 게시-구독 모델에서는 모든 구독자가 동일한 메시지를 받기 떄문에 이것이 불가능하다.
- 즉, 해당 모델에서는 하나의 메시지가 모든 구독자에게 복사되어 전달이 된다. 예를 들어서, 메시지 A가 발행되면 구독자 1, 2, 3에게 모두 동일한 메시지 A가 전달이 된다.
1. 게시자(Publisher) → 데이터(Data) → PubSub(Publisher Subsciber)
- 게시자는 애플리케이션이나 서비스를 의미하며, 데이터를 스트림 형태로 발행(Publish)합니다.
2. PubSub(Publisher Subsciber) → 구독자(Subscriber)
- 발행된 스트림 데이터는 이를 구독(Subscribe)하고 있던 모든 구독자(Subsciber)에게 전달이 됩니다.
- 전달된 구독자는 Single Consumer에게 전달되거나 혹은 여러 Consumer(Consumer Group)에게 다시 전달이 됩니다.
Apache Kafka 구요소
- 각 요소들은 유기적으로 연결되어 분산 스트리밍 플랫폼으로서의 기능을 수행합니다.
| 구성 요소 | 설명 | 주요 특징 |
| 생성자(Producer) | 메시지를 생성하고 발행하는 애플리케이션 | - 동기/비동기 전송 지원 - 파티션 분배 역할 - 메시지 신뢰성 보장 |
| 소비자(Consumer) | 토픽으로부터 메시지를 구독하고 읽는 애플리케이션 | - 메시지 오프셋 관리 - 자동/수동 커밋 - 병렬 처리 가능 |
| 소비자 그룹(Consumer Group) | 협력하여 메시지를 처리하는 소비자들의 집합 | - 자동 로드 밸런싱 - 장애 복구 기능 - 파티션별 할당 |
| 파티션(Partition) | 토픽을 나누는 물리적 단위 | - 병렬 처리 지원 - 순서 보장 - 확장성 제공 |
| 토픽(Topic) | 메시지가 저장되는 논리적 단위 | - 카테고리 분류 - 다중 구독 가능 - 영구 저장소 |
| 오프셋(Offset) | 파티션 내 각 메시지의 고유한 위치 식별자 | - 메시지 순서 보장 - 소비 위치 추적 - 재처리 가능 |
| 브로커(Broker) | 카프카 서버 | - 메시지 저장/관리 - 복제 관리 - 장애 복구 |
| 카프카 클러스터(Kafka Cluster) | 여러 브로커들의 분산 시스템 집합 | - 고가용성 보장 - 확장성 제공 - 부하 분산 |
1. 생성자(Producer)
- Kafka에서 메시지를 생성하고 발행하는 애플리케이션이나 서비스를 의미
- 동기/비동기 전송을 지원하고, 다양한 설정으로 성능과 신뢰성을 조절할 수 있다.
- 생성된 메시지를 토픽의 특정 파티션에 분배하는 역할을 한다.
| 기능 | 설명 | 세부 사항 |
| 메시지 발행 | 토픽에 데이터를 전송하는 역할을 담당합니다. | |
| 파티션 할당 | 메시지를 특정 토픽의 파티션에 분배하는 역할을 합니다. | - Round-Robin: 순차적으로 파티션에 할당 - Key-based: 메시지 키를 기반으로 특정 파티션에 할당 - Custom: 사용자 정의 파티션 전략 사용 |
| 신뢰성 보장 | 메시지 전송의 신뢰성 수준을 설정합니다. | - acks=0: 메시지 전송 후 응답을 기다리지 않음 - acks=1: 리더 파티션의 응답만 기다림 - acks=all: 모든 복제본의 응답을 기다림 |
| 배치 처리 | 성능 향상을 위해 여러 메시지를 묶어서 한 번에 전송할 수 있습니다. |
2. 소비자(Consumer)
- Kafka Topic으로부터 메시지를 구독(Subscribe)하고 읽어오는 애플리케이션이나 서비스를 의미.
- 하나 이상의 토픽을 구독(Subscribe)하여 메시지를 지속적으로 소비한다. 구독 과정에서 특정 토픽의 파티션에 할당되어 메시지를 읽어온다.
- Consumer Group을 통해 여러 Consumer가 협력하여 병렬 처리가 가능하다.
| 기능 | 설명 | 세부 사항 |
| 메시지 소비 | 토픽으로부터 메시지를 읽어오는 기본적인 기능을 수행합니다. | - 자동/수동 커밋 지원 - 오프셋 관리 |
| Consumer Group | 여러 Consumer를 그룹화하여 병렬 처리를 가능하게 합니다. | - 파티션당 하나의 Consumer 할당 - 자동 로드 밸런싱 - Failover 지원 |
| 오프셋 관리 | 메시지 소비 위치를 추적하고 관리합니다. | - earliest: 가장 처음부터 소비 - latest: 최신 메시지부터 소비 - 특정 오프셋부터 소비 |
| 재조정(Rebalancing) | Consumer Group 내에서 파티션을 재분배합니다. | - Consumer 추가/제거시 자동 재조정 - 장애 발생시 자동 복구 |
3. 소비자 그룹 (Consumer Group)
- 하나의 토픽에 대해 협력하여 메시지를 처리하는 소비자(Consumer)들의 집합을 의미한다. 즉, 동일한 토픽을 구독하는 소비자들의 논리적인 그룹이다.
- 하나의 파티션은 동일한 Consumer Group 내에서 하나의 Consumer에만 할당된다.
- 파티션의 수보다 Consumer가 많으면 일부 Consumer는 유휴 상태가 된다.
- 예를 들어서 하나의 토픽에는 3개의 파티션이 있고 Consumer Group 내에 2개의 Consumer가 있다고 가정한다.
- 이때는, Consumer 1은 파티션 1, 2를 처리하고, Consumer 2는 파티션 3을 처리하여 하나의 토픽에 대해 협력하여 처리한다.
유휴 상태?? : 컴퓨터 시스템이 사용 가능한 상태이나 실제적인 작업이 없는 상태
| 기능 | 설명 | 세부사항 |
| 로드 밸런싱 | 파티션을 Consumer들에게 균등하게 분배합니다. | - 자동 파티션 할당 - Consumer 수에 따른 동적 조정 - 효율적인 부하 분산 |
| 장애 복구 | Consumer 장애 시 자동으로 재조정됩니다. | - 자동 리밸런싱 - 장애 Consumer 감지 - 파티션 재할당 |
| 확장성 | Consumer를 추가하여 처리량을 증가시킬 수 있습니다. | - 동적 Consumer 추가/제거 - 수평적 확장 가능 - 파티션 수 제한 |
| 오프셋 관리 | 그룹 단위로 메시지 소비 위치를 추적합니다. | - 중복 처리 방지 - 그룹별 독립적 관리 - 커밋 포인트 저장 |
[ 더 알아보기 ]
💡 Consumer Group 병렬 처리는 어떻게 수행이 될까?
- 예를 들어서, 하나의 토픽 내에 파티션이 6개가 있고, Consumer Group 내에는 3명이 있다고 가정하자
- 이때, Consumer 1은 P1, P2를 처리하고 Consumber2는 P3, P4를 처리하고 Consumer 3에서는 P5, P6를 처리합니다.
- 이를 통해서 독립적으로 분산 처리를 수행하게 됩니다.
4. 메시지(Message)
- Kafka에서 데이터를 전송하는 기본 단위이다.
- 키(Key), 값(Value), 타임스탬프(Timestamp)로 구성되며, 선택저긍로 헤더(Headers)를 포함할 수 있다.
- 메시지는 한번 기록되면 변경할 수 없는 불변(lmmutable) 특성을 가진다.
| 구성요소 | 설명 | 특징 |
| 키(Key) | 메시지를 식별하는 선택적 메타데이터 | - 파티션 결정에 사용 - 동일한 키는 동일한 파티션에 저장 - null 가능 |
| 값(Value) | 실제 전송하려는 데이터 내용 | - 바이트 배열 형태로 저장 - 다양한 형식 지원 (JSON, Avro, 등) - 압축 가능 |
| 타임스탬프 | 메시지가 생성된 시간 정보 | - 메시지 순서 보장 - 데이터 추적 - 보존 정책에 활용 |
| 헤더 | 추가적인 메타데이터를 저장 | - 키-값 쌍으로 구성 - 선택적 사용 - 애플리케이션별 커스텀 정보 저장 |
5. 파티션(Patition)
- 토픽을 여러 개의 파티션으로 나누어 병렬 처리를 가능하게 하는 물리적 단위
- 각 파티션은 순서가 있는 불변의 시퀀스로 구성되며, 고유한 오프셋을 가진다
- 파티션을 통해 데이터를 여러 브로커에 분산 저장하여 높은 처리량과 확장성을 제공
| 기능 | 설명 | 세부사항 |
| 병렬 처리 | 토픽의 데이터를 여러 파티션으로 분할하여 동시 처리를 가능하게 합니다. | - 높은 처리량 제공 - 수평적 확장성 지원 - 다중 컨슈머 병렬 처리 |
| 순서 보장 | 각 파티션 내에서 메시지의 순서가 보장됩니다. | - 파티션 내 순차적 오프셋 - FIFO(First In First Out) 방식 - 파티션 간 순서는 보장되지 않음 |
| 복제 | 데이터 안정성을 위해 파티션을 여러 브로커에 복제합니다. | - 리더-팔로워 구조 - 복제 팩터 설정 - 자동 장애 복구 |
| 로드 밸런싱 | 파티션을 통해 브로커 간 부하를 분산합니다. | - 균등한 데이터 분배 - 효율적인 리소스 활용 - 동적 파티션 재분배 |
6. 토픽(Topic)
- Kafka에서 메시지가 저장되는 논리적인 채널 또는 피드의 이름
- 생성자(proceduer)가 메시지를 발행하고 소비자(consumer)는 이를 구독하는 대상이 된다.
- 하나의 토픽은 여러 개의 파티션으로 분할될 수 있다.
| 기능 | 설명 | 세부사항 |
| 메시지 구성 | 토픽은 관련된 메시지들의 스트림을 구성합니다. | - 메시지는 키-값 쌍으로 구성 - 시간 순서로 저장 - 고유한 오프셋 보유 |
| 확장성 | 파티션을 통해 수평적 확장이 가능합니다. | - 다수의 파티션으로 분할 가능 - 파티션별 독립적 처리 - 병렬 처리 지원 |
| 데이터 보존 | 설정된 보존 정책에 따라 메시지를 유지합니다. | - 시간 기반 보존 - 크기 기반 보존 - 압축 로그 지원 |
| 접근 제어 | 토픽별로 접근 권한을 관리할 수 있습니다. | - 읽기/쓰기 권한 설정 - ACL 기반 보안 - 다중 구독자 지원 |
7. 오프셋 (Offset)
- 파티션 내에서 각 메시지를 고유하게 식별하는 순차적인 ID 번호
- 파티션 내에서 순차적으로 증가하는 정수값으로, 메시지의 위치를 나타낸다.
- Consumer가 어디까지 메시지를 읽었는지 추적하는 데 사용된다.
- 예를 들어서, 데이터 1, 2, 3, 4, 5, 6이라는 값이 순차적으로 Topic 내에 파티션에 들어있다고 가정하에 Consumer는 3개 있을 때가 가정하에 있다.
- 이는 Consumer Group을 이루어서 Consumer 1은 1, 4 오프셋을 찾아서 데이터를 가져오고, Consumer2는 2, 5를 가져오고 Consumer3은 3, 6의 값을 가져오는 서로 다른 파티션을 병렬 처리를 수행한다.
💡 아래의 그림에서 Consumer 1, Consumer2에서는 Topic 내에 Partition을 가져오는 역할을 수행하고 있다.
- Consumer 1은 offset 4라는 값과 Consumer2는 offeset 3이라는 값을 가리키고 있어서 각각의 순차적인 ID 번호 값을 가져오는 역할을 수행합니다.
| 구성요소 | 설명 | 세부사항 |
| 시작 오프셋 | 파티션에서 가장 오래된 메시지의 위치 | - earliest: 가장 처음 메시지부터 읽기 - 보관 정책에 따라 변경될 수 있음 |
| 현재 오프셋 | Consumer가 현재까지 읽은 위치 | - Consumer Group별로 관리 - 자동/수동 커밋 가능 |
| 최신 오프셋 | 파티션에서 가장 최근에 추가된 메시지의 위치 | - latest: 최신 메시지부터 읽기 - Producer가 새 메시지 추가시 증가 |
| 커밋된 오프셋 | Consumer가 성공적으로 처리했다고 표시한 위치 | - 중복 처리 방지 - 장애 복구시 활용 - Consumer Group별 독립적 관리 |
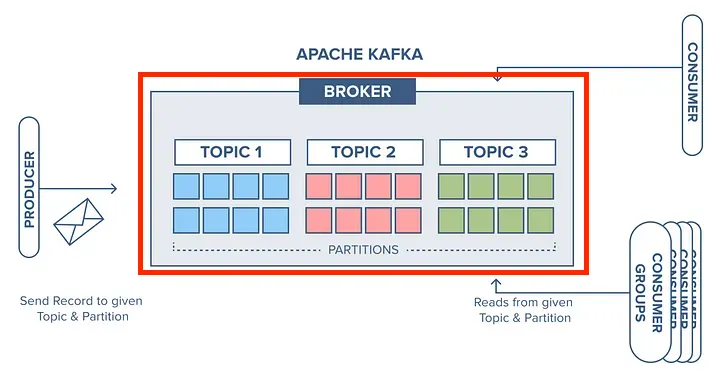
8. 브로커 (Broker)
- Kafka 클러스터를 구성하는 서버 단위입니다. 이는 메시지를 수신하고 저장을 담당하는 역할을 의미합니다.
- 생성자(Producer)로부터 전달받은 토픽의 파티션을 저장하고 관리하는 역할을 합니다.
- 소비자(Consumer)로부터 요청에 따라 저장된 메시지를 전달하는 역할을 수행합니다.
- 생성자와 소비자 간의 메시지 전달을 중개하는 역할을 수행합니다.
- 카프카 클러스터(Kafka Cluster)내에서 각 브로커 마다 고유한 ID를 가지며, 다른 브로커들과 협력하여 데이터를 복제하고 동기화를 수행합니다.
| 기능 | 설명 | 세부 사항 |
| 메시지 저장 | 토픽의 파티션을 디스크에 저장하고 관리합니다. | - 설정된 보관 기간 동안 메시지 보존 - 디스크 기반 저장으로 영속성 보장 |
| 복제 관리 | 데이터의 안정성을 위해 파티션 복제본을 관리합니다. | - 리더와 팔로워 파티션 관리 - 자동 장애 복구 지원 - 복제 팩터 설정 가능 |
| 부하 분산 | 클러스터 내에서 데이터와 요청을 분산 처리합니다. | - 파티션의 균등한 분배 - 네트워크 트래픽 분산 - 리소스 사용 최적화 |
| 컨트롤러 기능 | 클러스터 내 리더 선출과 관리를 담당합니다. | - 브로커 상태 모니터링 - 파티션 리더 선출 - 클러스터 메타데이터 관리 |
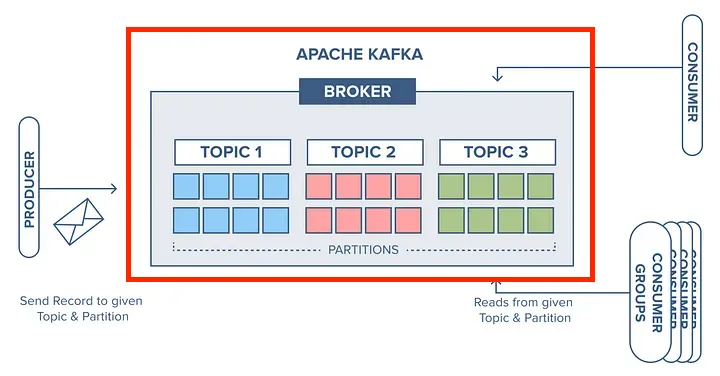
9. 클러스터(Cluster)
- 여러 대의 브로커(Broker)들이 모여 구성된 분산 시스템이다.
- 각 브로커들은 서로 협력하여 데이터를 안전하게 저장하고 처리한다.
| 기능 | 설명 | 세부사항 |
| 고가용성 | 클러스터 내 복제를 통해 안정성을 보장합니다. | - 브로커 장애 시 자동 복구 - 데이터 복제 - 무중단 운영 지원 |
| 확장성 | 필요에 따라 브로커를 추가하여 확장할 수 있습니다. | - 수평적 확장 가능 - 동적 클러스터 조정 - 부하 분산 |
| 관리 기능 | 클러스터의 상태를 모니터링하고 관리합니다. | - 브로커 상태 감시 - 리소스 사용량 추적 - 성능 모니터링 |
| 데이터 분산 | 여러 브로커에 걸쳐 데이터를 분산 저장합니다. | - 파티션 분산 - 균형있는 저장소 사용 - 효율적인 데이터 접근 |
출처
전 이분의 기록을 따라 쓰면서 공부만 했습니다. 공부하실려면 이분꺼 보세용 설명 기깔납니다!!
[OpenSource] Apache Kafka 이해하기 -1: 주요 모델 및 구성요소
해당 글에서는 Apache Kafka에 대해 이해를 돕기 위해 작성한 글입니다. 💡 [참고] Docker 기반의 초기 Apache Kafka 구성이나 혹은 Apache Kafka 이론에 대해 궁금하시면 아래의 글을 참고하시면 도움이
adjh54.tistory.com
'Spring' 카테고리의 다른 글
| [Spring] Spring Boot WebSocket + STOMP 사용해서 단체 채팅 구현하기 (0) | 2025.03.31 |
|---|---|
| [Spring] Spring Boot WebSocket + STOMP 구성요소 (0) | 2025.03.30 |