팔로우 구현하기
사전 준비 : 프로필 페이지 준비하기
프로필 구현(1/5)
- url 작성

프로필 구현(2/5)
- view 함수 작성

프로필 구현(3/5)
- profile 템플릿 작성
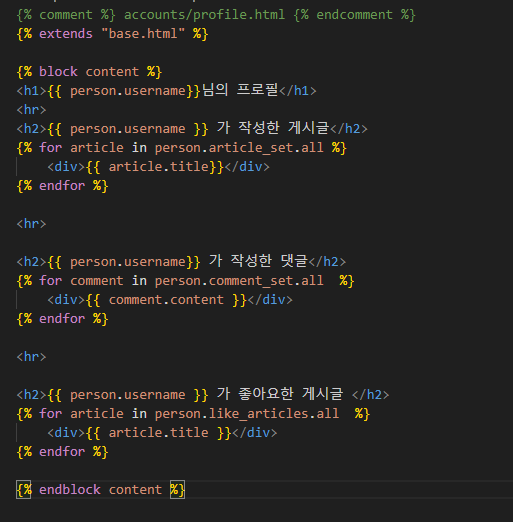
프로필 구현(4/5)
- 프로필 페이지로 이동할 수 있는 링크 작성


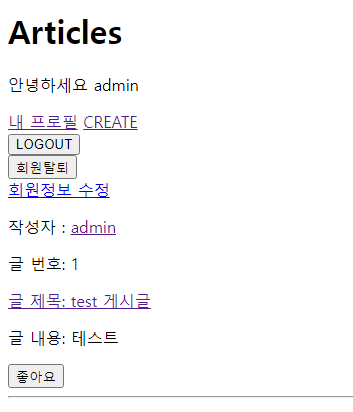
프로필 구현(5/5)
- 프로필 페이지 결과 확인

모델 관계 설정
User(M) - User(N)
- 0명 이상의 회원은 0명 이상의 회원과 관련
- 회원은 0명 이상의 팔로워를 가질 수 있고, 0명 이상의 다른 회원들을 팔로잉 할 수 있음
모델 관계 설정 (1/2)
ManyToManyField 작성

- 참조
- 내가 팔로우 하는 사람들 (팔로잉, followings)
- 역참조
- 상대방 입장에서 나는 팔로워 중 한 명 (팔로워, followers)
바뀌어도 상관 없으나 관계 조회 시 생각하기 편한 방향으로 정할 것
모델 관계 설정 (2/2)
- Migrations 진행 후 중개 테이블 확인

기능 구현
기능 구현(1/4)
- url 작성

기능 구현(2/4)
- view 함수 작성

기능 구현(3/4)
- 프로필 유저의 팔로잉, 팔로워 수 & 팔로우, 언팔로우 버튼 작성

기능 구현(1/4)

Fixtures
Django 가 데이터베이스로 가져오는 방법을 알고 있는 데이터 모음
→ 데이터는 데이터베이스 구조에 맞추어 작성 되어 있음
사용 목적
- 초기 데이터 제공
초기 데이터의 필요성
- 프로젝트의 앱을 처음 설정할 때 동일하게 준비 된 데이터로 데이터베이스를 미리 채우는 것이 필요한 순간이 있음
→ Django 에서는 fixtures을 사용해 앱에 초기 데이터(initial data)를 제공
fixtures 관련 명령어
- dumpdata : 생성(데이터 추출)
- loaddata : 로드 (데이터 입력)
dumpdata
데이터베이스의 모든 데이터를 추출


모든 모델을 한꺼번에 dump 하기
- 데이터 관리가 어렵기 때문에 권장하지는 않는다.

Fixtures 파일을 직접 만들지 말 것!!
loaddata
Fixtures 데이터를 데이터베이스로 불러오기
약속된 load하는 경로
Fixtures 파일 기본 경로
- app_name/fixtures
→ Django는 설치된 모든 app의 디렉토리에서 fixtures 폴더 이후의 경로로 fixtures 파일을 찾아 load


loaddata 순서 주의사항
- 만약 loaddata를 한번에 실행하지 않고 별도로 실행한다면 모델 관계에 따라 load 순서가 중요할 수 있음
- comment는 article에 대한 key 및 user에 대한 key가 필요
- article은 user에 대한 key가 필요
- 즉, 현재 모델 관계에서는 user → article → comment 순으로 data를 load 해야 오류가 발생하지 않는다
loaddata 시 encoding codec 관련 에러가 발생하는 경우 해결방법!!
- 메모장 활영
- 메모장으로 json 파일 열기
- "다른 이름으로 저장" 클릭
- 인코딩을 UTF8로 선택 후 저장
- dumpdata 시 추가 옵션 작성

Improve query
"query 개선하기"
→ 같은 결과를 얻기 위해 DB 측에 보내는 query 개수를 점차 줄여 조회하기
annotate
- SQL의 GROUP BY를 사용
- 쿼리셋의 각 객체에 계산된 필드를 추가
- 집계 함수(Count, Sum 등)와 함께 자주 사용됨
annotate 예시

- 의미
- 결과 객체에 'num_authors' 라는 새로운 필드를 추가
- 이 필드는 각 책과 연관된 저자의 수를 계산
- 결과
- 결과에는 기존의 필드와 함계 'num_authors' 필들를 가지게 됨
- book.num_authors로 해당 책의 저자 수에 접근할 수 있게 됨
annotate 적용해보기
Django 디버크 툴바 확장프로그램 활용
문제 상황
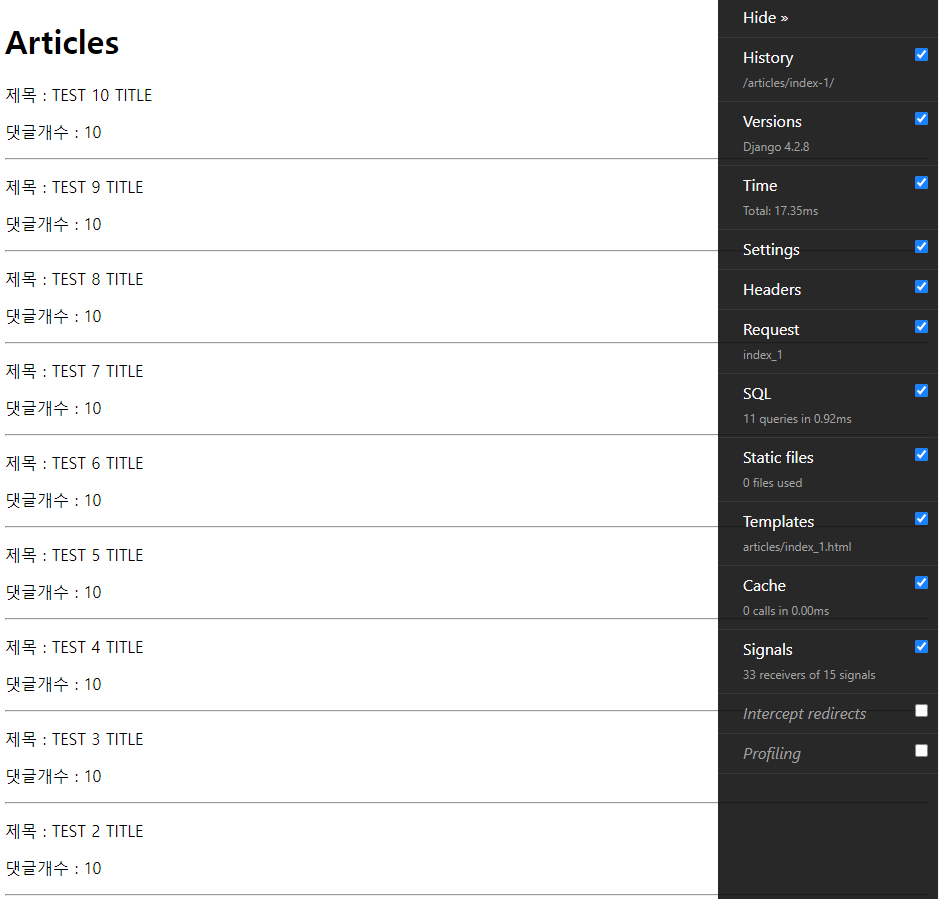
모든 게시글을 출력하는데 + 댓글 개수도 같이 출력
→ 각 게시글마다 댓글 개수를 반복 평가하기 때문에 이 데이터를 얻기 위해 총 11번의 SQL 문을 보냄

문제해결
게시글을 조회하면서 댓글 개수까지 한번에 조회해서 가져오기


article.comment__count : 실제로 존재하는 테이블이 아니라 이름을 지정하지 않으면 이름이 이상하게 만들어짐
select_related
- SQL의 INNER JOIN을 사용
- 1:1 또는 N:1 참조 관계에서 사용
- ForeignKey나 OneToOneField 관계에 대해 JOIN을 수해
- 단일 쿼리로 관련 객체를 함께 가져와 성능을 향상
select_related 예시

- 의미
- Book 모델과 연관된 Publisher 모델의 데이터를 함께 가져옴
- ForeignKey 관계인 'publisher'을 JOIN하여 단일 쿼리 만으로 데이터를 조회
- 결과
- Book 객체를 조회할 때 연관된 Publisher 정보도 함께 로드
- book.publisher.name과 같은 접근이 추가적인 데이터베이스 쿼리 없이 가능
select_related 적용해보기
Django 디버크 툴바 확장프로그램 활용
문제 상황

모든 게시글을 출력하는데 + 각각의 게시글에 작성자 이름도 출력되고 있음
→ 각 게시글마다 댓글 개수를 반복 평가하기 때문에 이 데이터를 얻기 위해 총 11번의 SQL 문을 보냈는데 10개가 비슷하고 8개가 중복인 상황

문제해결
문제 원인
- 각 게시글마다 작성한 유저명까지 반복 평가

게시글을 조회하면서 유저 정보까지 한번에 조회해서 가져오기


prefetch_related
- SQL이 아닌 Python을 사용한 JOIN을 진행
- 관련 객체들을 미리 가져와 메모리에 저장하여 성능을 향상
- M:N 또는 N:1 역참조 관계에서 사용
- ManyToManyField나 역참조 관계에 대해 별도의 쿼리를 실행
prefetch_related 예시

- 의미
- Book과 Author는 ManyToMany 관계로 가정
- Book 모델과 연관된 모든 Author 모델의 데이터를 가져옴
- Django가 별도의 쿼리로 Author 데이터를 가져와 관계를 설정
- 결과
- Book 객체들을 조회한 후, 연관된 모든 Author 정보가 미리 로드 됨
- for author in book.authors.all()와 같은 반복이 추가적인 데이터 베이스 쿼리 없이 실행됨
prefetch_related 적용해보기
문제 상황

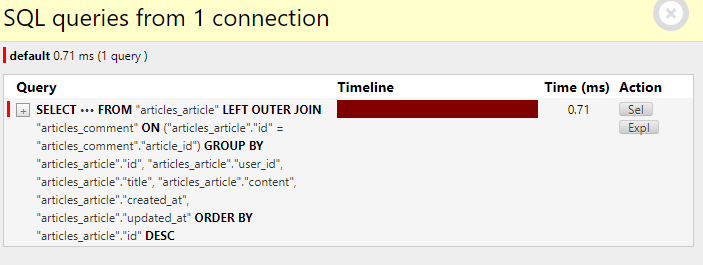
모든 게시글을 출력하는데 + 각각의 게시글에 작성된 댓글의 목록도 출력되고 있음
→ 각 게시글마다 댓글 개수를 반복 평가하기 때문에 이 데이터를 얻기 위해 총 11번의 SQL 문을 보냈는데 10개가 비슷한 상황
문제해결
문제 원인
- 각 게시글 출력 후 각 게시글의 댓글 목록까지 개별적으로 모두 평가

게시글을 조회하면서 참조된 댓글까지 한번에 조회해서 가져오기
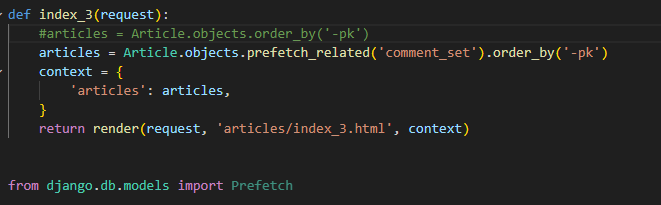

select_related & prefetch_related 적용해보기
문제 상황


모든 게시글을 출력하는데 + 각각의 게시글에 작성된 댓글의 목록 + 거기에 각각의 게시글 댓글의 작성자 이름도 출력되고 있음
→ 각 게시글마다 댓글 개수를 반복 평가하기 때문에 이 데이터를 얻기 위해 총 111번의 SQL 문을 보냈는데 100개가 비슷한 상황
문제 해결
문제 원인
- "게시글" + "각 게시글의 댓글 목록" + "댓글의 작성자"를 단계적으로 평가하고 있음

- "게시글(1)" → "각 게시글의 댓글 목록(N)" = prefetch_related
- "각 게시글의 댓글 목록(N)" + "댓글의 작성자(1)" = select_related로 해결


섣부른 최적화는 악의 근원!!
"작은 효율성에 대해서는, 말하자면 97% 정도에 대해서는, 잊어버려라. 섣부른 최적하는 모든 악의 근원이다
- 도널드 커누스(Donald E. Knuth)
참고
'exist' method
.exists()
- QuerySet에 결과가 하나 이상 존재하는지 여부를 확인하는 메서드
- 결과가 포함되어 있으면 True를 반환하고 결과가 포함되어 있지 않으면 False를 반환함
특징
- 데이터베이스에 최소한의 쿼리만 실행하여 효율적
- 전체 QuerySet을 평가하지 않고 결과의 존재 여부만 확인
→ 대량의 QuerySet에 있는 특정 객체 검색에 유용
적용 예시


'Django' 카테고리의 다른 글
| DRF02-with N:1 Relation [django] (0) | 2024.10.17 |
|---|---|
| DRF 01 [Django] (0) | 2024.10.16 |
| Many to Many Relationships 01 [Database] (1) | 2024.10.14 |
| Many to one relationships 2 [Database] (0) | 2024.10.11 |
| Many to one relationships 01 [Database] (1) | 2024.10.11 |